一、对象、类、元类的
isa指针和superClass指针指向讲解二、类、元类的
methods成员变量详解三、类、元类的
cache成员变量详解
一、对象、类、元类的isa指针和superClass指针指向讲解
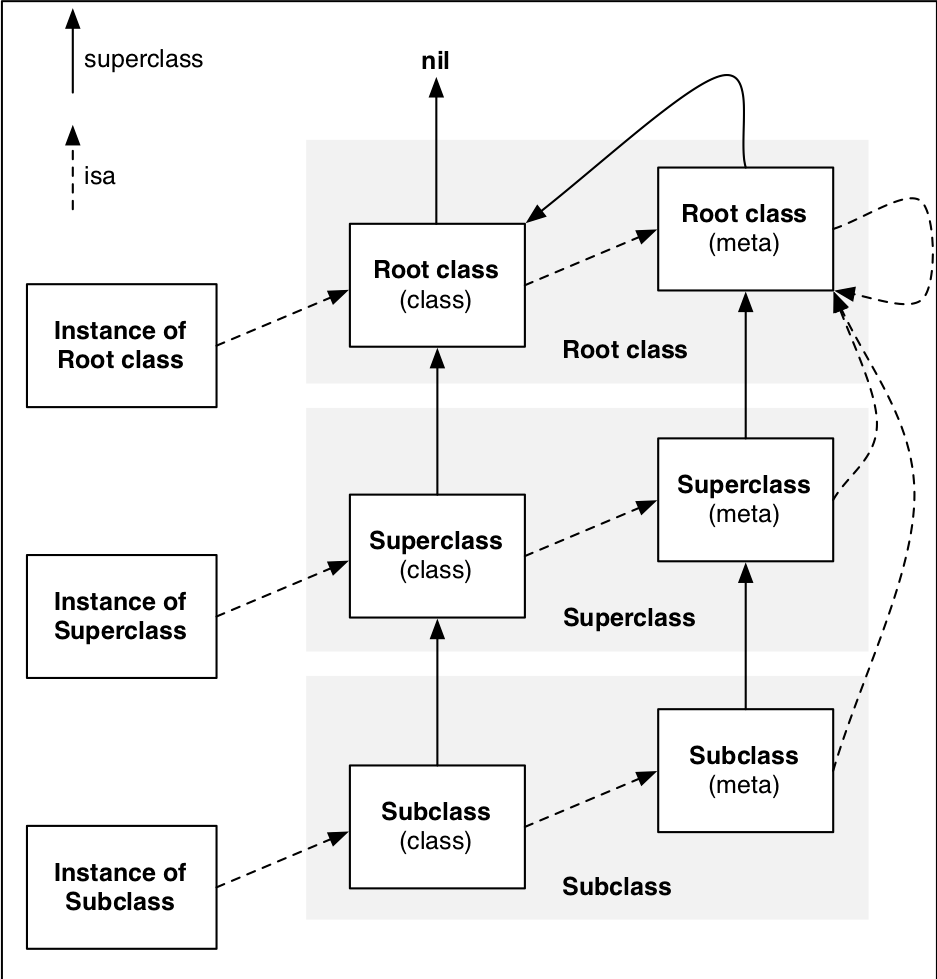
isa指针和superclass指针是两个非常重要的指针,弄清它俩的指向有助于我们理解很多东西。
概括地说:**isa指针指向它所属的类,superclass指针指向它的父类。**
具体地说:
- 实例对象的
isa指针指向它所属的类,类的isa指针指向它的元类,元类的isa指针指向基类的元类,基类的元类的isa指针指向它自己。(isa指针体系中基类的元类是终结) - 子类的
superclass指针指向它的父类,这样一层一层往上直到基类,基类的superclass指针为nil;子元类的superclass指针指向父元类,这样一层一层往上直到基类的元类,基类的元类的superclass指针指向基类。(superclass指针体系中nil是终结)
二、类、元类的methonds成员变量详解
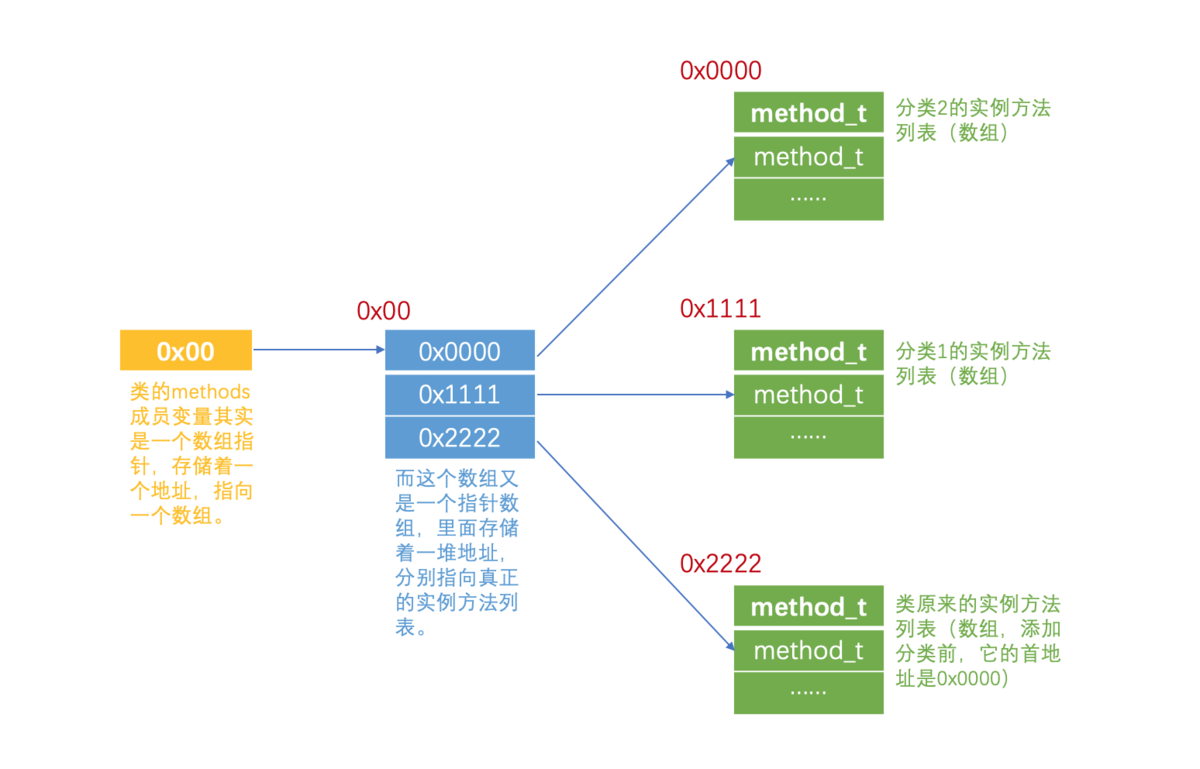
我们知道了类的methods成员变量存储着该类所有的实例方法信息,那它到底是怎么存储的?类的methods成员变量其实是一个数组指针,也就是说methods成员变量里存储着一个地址,只占了8个字节,指向一个数组。而这个数组又是一个指针数组,这个数组的大小要看这个类有几个分类,假设有N个分类,那么它就占了(N + 1) * 8个字节,也就是说这个数组里存储着一堆地址,分别指向真正的实例方法列表,这些实例方法列表包括分类2的实例方法列表、分类1的实例方法列表、类本身的实例方法列表等等,方法列表里才存放着一个一个的实例方法method_t,一个method_t结构体里有3个指针,所以它占用了24个字节,这些内存都是在静态全局区的,它们的大小其实占不了多少,一个App真正占用内存的是我们用这些类alloc init出来的一个个对象,还有图片资源。元类的methods成员变量也是一样的存储方式,只不过里面存储的是该类所有的类方法信息。
通过查看Runtime的源码(objc-runtime-new.h文件),我们得到方法的定义如下(伪代码):
1 | struct method_t { |
可见方法的本质就是一个method_t类型的结构体,该结构体内部有三个成员变量:
SEL:方法选择器,跟方法名一一对应,是一个方法的唯一标识,我们直接把它当作方法名来看待就行,可以通过@selector(方法名)、NSSelectorFromString(@"方法名的OC字符串")、sel_registerName("方法名的C字符串")来获取方法选择器;types:类型编码字符串,包含了方法的参数和返回值信息,这里是类型编码对照表,类型编码中第一个字母代表该方法的返回值类型,后面的字母依次代表该方法的各个参数类型;第一个数字代表该方法所有参数占用内存的总大小,后面的数字依次代表该方法各个参数的内存地址距离内存首地址的偏移量;IMP:函数指针,存储着一个地址,只想该方法在代码区的具体实现。
三、类、元类的cache成员变量详解
我们知道一个对象接收到消息,会根据它的isa指针找到他所属的类,然后根据类的methods成员变量找到所有的方法列表,然后依次遍历这些方法列表来查找要执行的方法。但实际情况中,一个对象只有一部分方法是常用的,其他的方法很少用到或根本用不到,那如果对象每接收一个消息就要遍历一次所有的方法列表,性能肯定会很差。类的cache成员变量就是用来解决问题的,对象每调用一个方法,系统就会把这个方法存储到cache中,下次对象调用方法时就会优先去cache中查找,如果找到方法则直接调用,如果找不到才去methods哪里找,这就大大提高了查找效率。而且cache还不是简单地存取方法,它用了散列表,这就使得方法查找的效率更高。
通过查看Runtime的源码(objc-runtime-new.h文件),我们得到cache的定义如下(伪代码):
1 | struct cache_t { |
可见cache的本质就是一个cache_t类型的结构体,该结构体内部有三个成员变量:
_buckets:方法缓存散列表;_mask:散列表的长度 - 1;_occupied:已缓存方法的数量。
散列表中的元素也不直接是方法——method_t,而是一个叫bucket_t的东西,它是用方法的SEL和IMP组成的结构体。(为方便叙述,下文中“方法”即指bucket_t)
关键词:散列表、表中元素、表中元素唯一标识、散列算法和散列函数、
index散列表(Hash Table,也叫哈希表),就是把表中元素的唯一标识通过某种算法得到一个
index,然后通过这个index直接访问表中元素的一种数据结构,这样就不用遍历了,因此可以大大提高数据查找的效率。实现这个算法的函数叫作散列函数,存储数据的数组叫作散列表(但这个数组不是普通的数组,它的元素可以不连续存储,因此散列表就有可能造成内存的空闲,它是一个典型的“以空间换时间”的例子)。散列表的核心就在于散列算法。
接下来我们就看看苹果是如何实现cache散列表的。
cache散列表的散列算法:
1 | unsigned int cache_hash(SEL sel, mask_t mask) |
可见苹果关于cache散列表的散列算法其实很简单,就是:用方法的SEL & (散列表的长度 - 1),这样就能得到一个index了,我们知道方法的SEL确实是表中元素的唯一标识。
cache散列表处理冲突
散列表都会存在的一个问题是:不同的唯一标识经过散列算法后可能得到相同的index,那这样数据存取就可能出现冲突,怎么处理呢?
1 | // 这里只是读取方法的源码,存储方法也是一样的道理 |
可见cache散列表处理冲突的方式为:index-1,然后遍历散列表,直到找到空闲的内存来存储方法,或者直到找到我们真正想读取的方法。
cache散列表存取数据
通过散列算法得到index之后,系统就会把这个方法直接存储到散列表相应的index处,因此这就可能造成内存的空闲。
而读取方法的时候也是先通过散列算法得到index,直接从相应的index处拿出方法,因此就不用遍历了,大大提高了方法查找的效率。
cache散列表扩容
1 | void cache_t::expand() |
随着散列表缓存的方法越来越多,它的内存可能就不够用了,此时系统会对散列表进行两倍扩容,创建一个新的散列表,释放旧的散列表并清空所有的方法缓存。