一、iOS内存管理方式:
1.Tagged Pointer:小对象的内存管理方式
2.引用计数:普通对象的内存管理方式
二、MRC介绍,需要开发工程师做哪些工作
三、ARC介绍,编译器帮我们做了什么
1.指针修饰符
1. __strong
2. __weak
3. __unsafe_unretained
4. __autoreease
2.属性修饰符
2.1 原子性:
atomic、nonatomic 2.2 读写权限:
readwrite、readonly 2.3 内存管理语义:
assign、retain、copy、strong、weak、unsafe_unretained
一、内存管理方式:
1.Tagged Pointer:小对象的内存管理方式
64位操作系统后,iOS引入了Tagged Pointer,用来优化NSString、NSNumber、NSDate的内存管理。
引入Tagged Pointer之前(32位操作系统时),小对象内存管理方式和普通对象一样,首先需要在堆区开辟一块内存,并把内存的地址赋值给栈区的指针变量,然后维护对象的引用计数和内存的释放。
比如我们创建一个int类型的NSNumber对象:
1 | NSNumber *number = @11; |
系统需要开辟16个字节的内存来存储11这个值,同时需要开辟8个字节大小的内存来存储这个对象的地址,本来需要占用4个字节的内存的Int类型数据,占用了24个字节,同时还没考虑维护引用计数和内存释放等的内存开销。
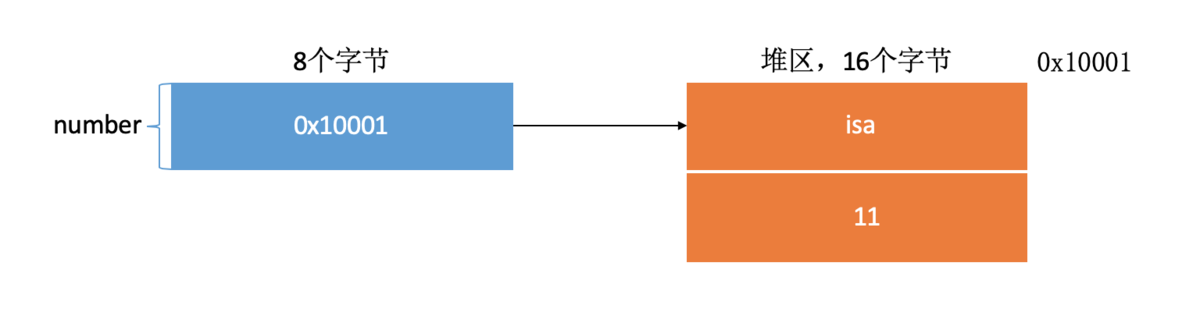
在引入Tagged Pointer之后,小对象就不需要像之前那样 在堆区开辟内存,维护引用计数,释放内存了。而是直接把值存到了number指针里,number里面存的不再是一个地址了,而是Tag + Data,Tag是用来标记小对象的类型(NSString、NSNumber、NSDate),Data就是小对象的值。指针什么时候创建,小对象就什么时候创建,指针什么时候销毁,小对象就什么时候销毁。只有在指针存不下小对象的值时,才会变为引用计数的方式管理内存。这样,仅需要8个字节就可以存储小对象的类型和值,很大程度上节省了内存占用,同时也减少了维护引用计数、内存释放等带来的开销。
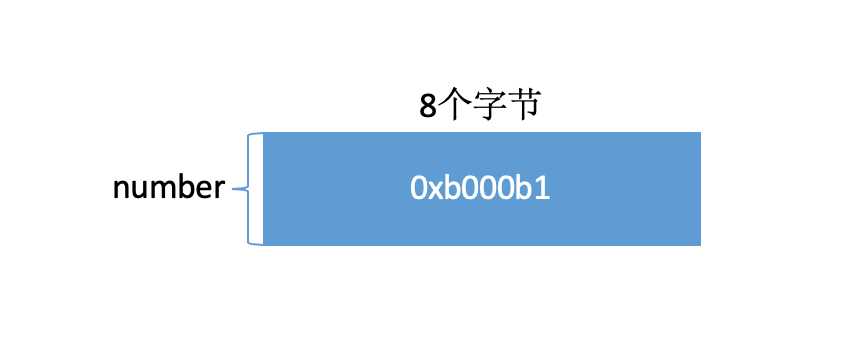
用代码验证一下:
1 | // 苹果对Tagged Pointer做了数据混淆,所以在分析Tagged Pointer之前,我们需要先关闭Tagged Pointer的数据混淆。通过设置环境变量OBJC_DISABLE_TAG_OBFUSCATION为YES。否则无法分析打印出的结果 |
number1~number3指针是Tagged Pointer,number4由于值大到存储不下了,改为普通对象内存管理方式。对应的地址分布规律见下图(mac os系统的规律与iOS系统的规律不同 详细),可发现规律如果一个指针的最高位为1,那么他就是Tagged Pointer,否则就不是。

如果是NSString的话,Tagged Pointer内存地址分布规律就是下面这样的:
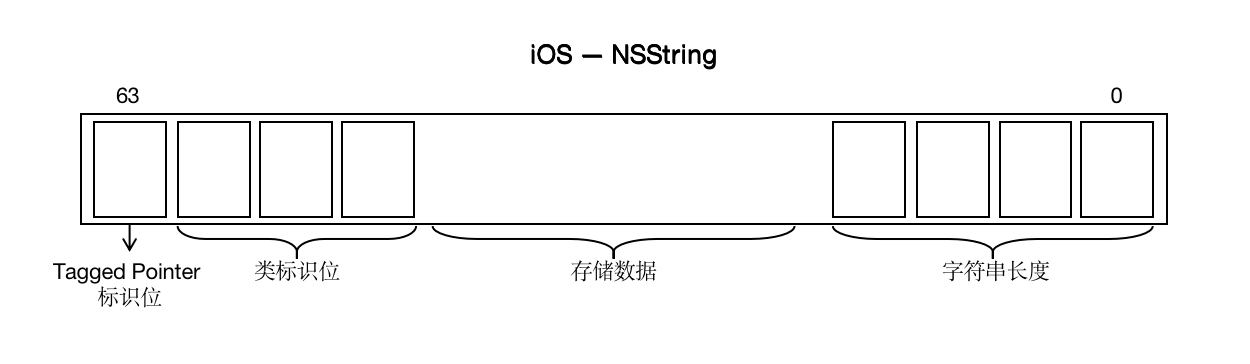
学习完上面内容,我们举个例子验证下,找不同:
1 | // 开辟多个线程去修改name属性 |
运行代码我们会发现 代码1 会crash,因为abcdefghijk已经大到指针存储不下,改为了普通对象内存管理方式,所以 代码1 就是正常的调用setter方法修改name属性,setter的实现是这样的:
1 | - (void)setName:(NSString *)name { |
在不加锁的情况下,极容易发生多个线程同时调用[_name release]的情况,若_name已经销毁,再次调用release肯定会发生crash。
代码2 正常运行,是因为abc并没有大到指针存储不下,NSString为NSTaggedPointerString类型,在objc_release函数中会判断指针是不是TaggedPointer类型,是的话就不对对象进行release操作,也就避免了因过度释放对象而导致的Crash,因为根本就没执行释放操作。
2.引用计数:普通对象的内存管理方式
2.1 引用计数是什么?
iOS是通过引用计数来管理内存的。所谓的引用计数就是指每当我们创建一个对象,系统就会为该对象分配一个整数,用来表征当前有多少人想使用该对象。那就引出两个问题:
问题1:创建对象时,系统为对象分配的整数存在哪里?也就是引用计数存在哪里?因为我们知道OC对象内部只有一个isa,并没有引用计数的成员变量
问题2:iOS具体是怎么通过引用计数来管理内存的?
2.2 引用计数存储在哪里?
64位操作系统以前,对象的isa指针还没进行内存优化,对象的引用计数存储在引用计数表里。
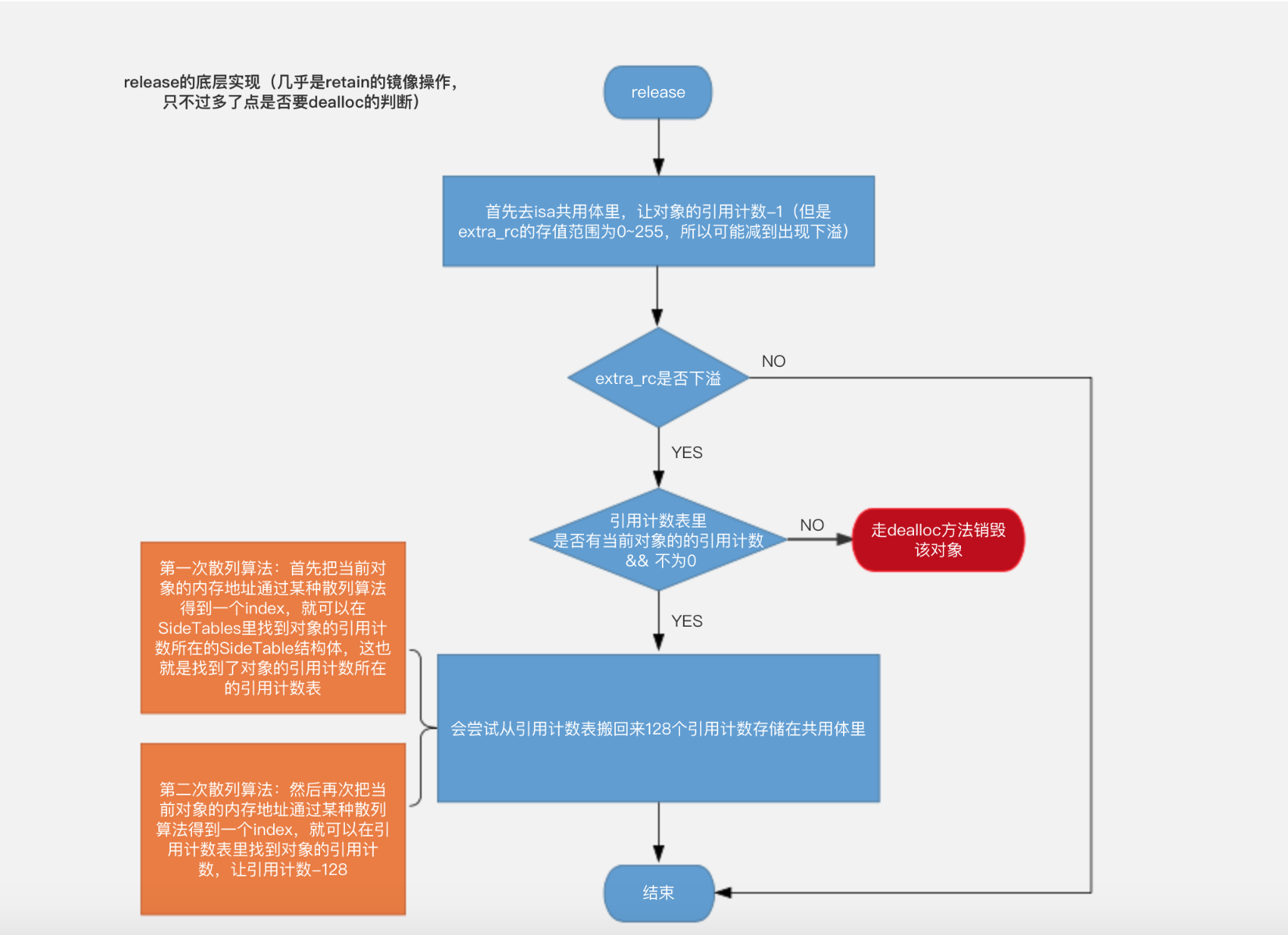
当系统为64位操作系统后,对象的isa指针经过了内存优化,它不再直接是一个指针了,而是一个共用体,64位中只有33位用来存储对象所属类的地址信息,还有19位用来存储(对象的引用计数 -1),还有1位用来标记引用计数表里是否有当前对象的引用计数。具体地说:对象的引用计数首先会存储在isa共用体里——extra_rc变量,但是isa共用体的引用计数存储范围是0~255,一旦引用计数超过了255,这个变量就会溢出,此时系统会把这个变量置为128,同时把引用计数表里是否有当前对象的引用计数的标记——has_sidetable_rc变量置为1,并把另外128个引用计数挪到引用计数表里进行存储。下一次对象的引用计数再次增加时,依旧增加isa共用体里的引用计数(因为它已被置为128,不再是溢出状态),直到再次溢出,系统再娜128个引用计数到引用计数表里,如此循环往复。
因此可以看出,系统是不会直接操作引用计数表里的引用计数的,而总是在操作isa共用体里的引用计数,直到溢出时才从isa共用体里挪128个引用计数到引用计数表里进行存储。
isa共用体1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28struct objc_object {
isa_t isa; // 一个isa_t类型的共用体
// 自定义的成员变量,存储着该对象这些成员变量具体的值
NSSring *_name; // “张三”
NSSring *_sex; // “男”
int _age; // 33
}
union isa_t {
Class cls;
unsigned long bits; // 8个字节,64位
struct { // 其实所有的数据都存储在成员变量bits里面,因为外界只访问它,而这个结构体则仅仅是用位域来增加代码的可读性,让我们看到bits里面相应的位上存储着谁的数据
unsigned long nonpointer : 1; // isa是否经过内存优化
unsigned long has_assoc : 1;
unsigned long has_cxx_dtor : 1;
unsigned long shiftcls : 33; // 对象所属类的地址信息
unsigned long magic : 6;
unsigned long weakly_referenced : 1;
unsigned long deallocating : 1;
unsigned long has_sidetable_rc : 1; // 引用计数表里是否有当前对象的引用计数
unsigned long extra_rc : 19; // 对象的引用计数 - 1
};
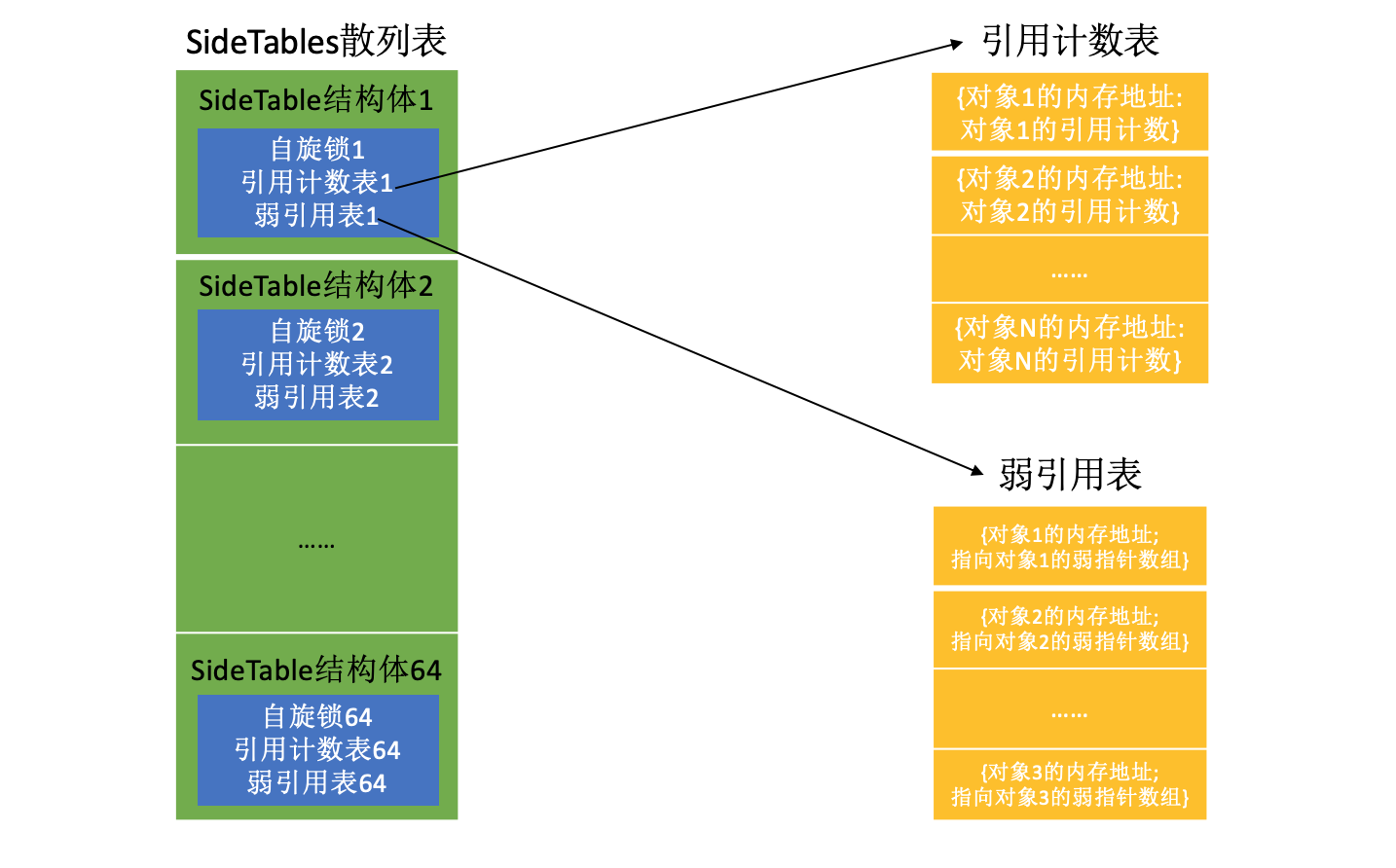
};SideTables–>SideTable–>引用计数表、若引用表
1 | static StripedMap<SideTable>& SideTables() { |
SideTables是一个全局的散列表,它里面存储着64个SideTable结构体,而每个SideTable结构体内部又存储着1个引用计数表和1个弱引用计数表,所以项目中一般会有64个引用计数表和64个弱引用计数表。引用计数表也是一个散列表,表中的元素是一个字典:key为对象的内存地址,value为对象的引用计数,引用计数表里存储着很多对象的引用计数。若引用计数表也是一个散列表,表中的元素是一个结构体:一个成员变量是对象的内存地址,另一个成员变量是指向该对象的弱指针数组。
所以如果我们想要找到对象的引用计数和弱指针数组,就要首先把对象的内存地址通过某种散列算法得到一个index,就可以在SideTables里找到对象的引用计数和弱指针数组所在的SideTable结构体,也就是找到了引用计数和弱指针数组所在的引用计数表和弱引用计数表,然后再次把对象的内存地址通过某种散列算法得到一个index,就可以在引用计数表里找到对象的引用计数,弱引用计数表里找到对象的弱指针数组了。
2.3 iOS具体是怎么通过引用计数来进行对象的内存管理的
主要是通过alloc、new、alloc、copy、mutableCopy,retain,release、autorelease,dealoc这几个方法操作引用计数,来管理对象内存管理的,即:
1 | // NSObject.mm |
关于
autorelease和autoreleasepool就暂时理解这么一点,更底层的东西有空再说:
release会立即使对象的引用计数-1,而autorelease则不会,它仅仅是把该对象注册到了autoreleasepool中,当autoreleasepool销毁时系统会自动让池中所有的对象都调用一下release,这时对象的引用计数才-1。- 而
autoreleasepool又是在RunLoop休眠或退出时销毁的,当然如果是我们自己创建的@autoreleasepool{},出了大括号——即出了@autoreleasepool{}的生命周期,它就会销毁。- 只要不是用
alloc、new、copy、mutableCopy方法创建的对象,而是用类方法创建的对象,方法内部都调用了autorelease,都是autorelease对象。
如果对象的引用计数减为0了,就代表没人想使用该对象了,系统就会调用
dealloc方法销毁它,并释放它对应的内存,对象一经销毁就不能再访问了,因为他的内存随时会被移作它用。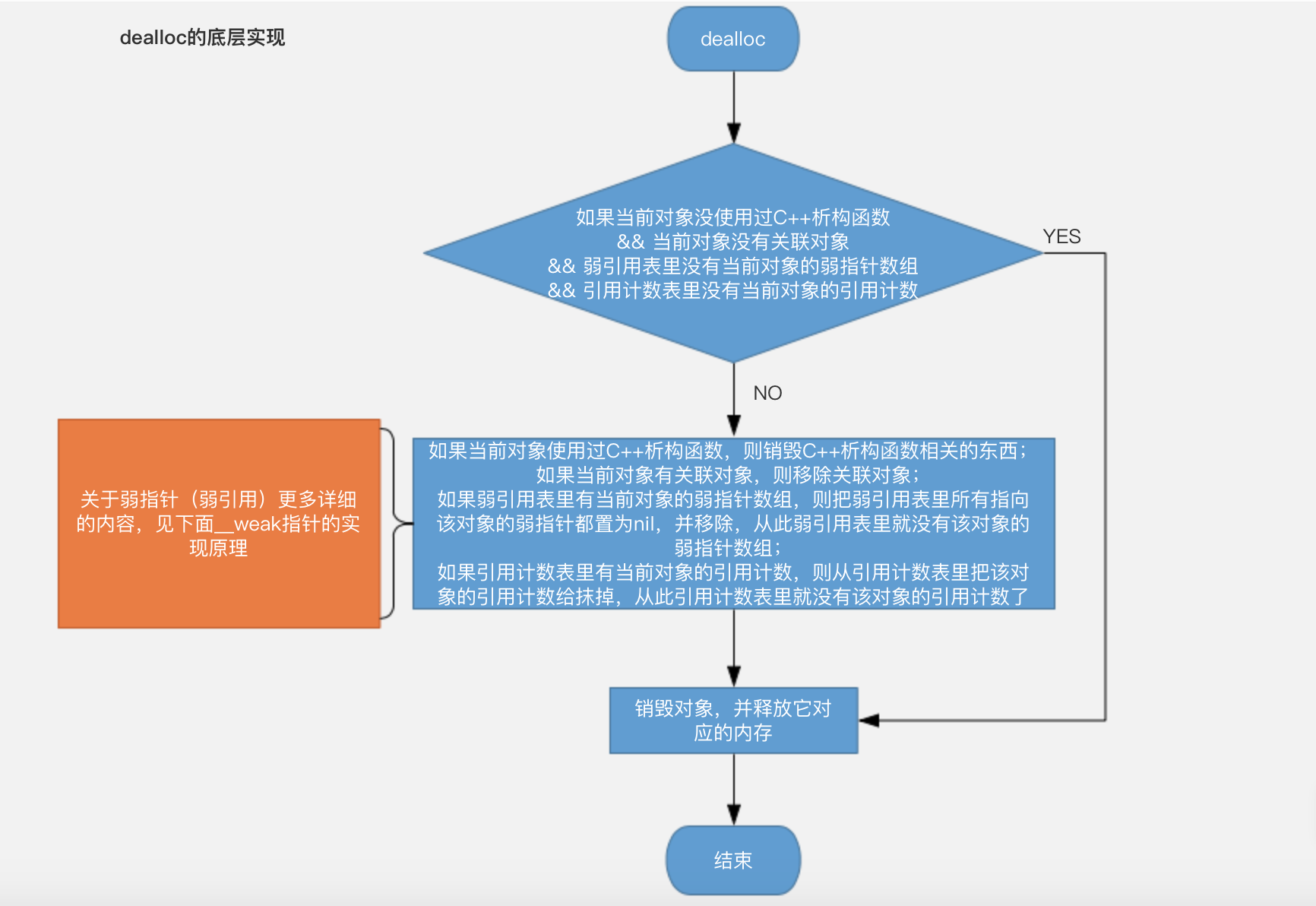
1 | // NSObject.mm |
二、MRC介绍,需要开发工程师做哪些工作
MRC(Manual Reference Count):指手动管理引用计数,即需要程序员自己手动调用上面那几个alloc、new、alloc、copy、mutableCopy,retain,release、autorelease,dealoc方法来操作引用计数,从而完成对象的内存管理。具体地说,MRC下我们需要做到以下三点:
- 调用了
alloc、new、alloc、copy、mutableCopy创建对象的地方,在不想使用对象时,要调用
release、autorelease;调用了retain使对象引用计数+1的地方,在不想使用对象时,要调用
release、autorelease来使对象的引用计数-1。
1 | - (void)viewDidLoad { |
- 我们还需要处理好
setter方法内部的内存管理,并在dealloc方法里释放当前类及其父类所有对象类型的成员变量。
1 | @implementation INEPerson { |
- 我们还需要处理好循环引入问题。
1 | // INEMan.h |
1 | // INEWoman.h |
1 | - (void)viewDidLoad { |
三、ARC介绍,编译器帮我们做了什么
ARC(Autal Reference Count):自动管理引用计数,让编译器进行内存管理,在LVVM编译器中设置ARC为有效状态,就无需再次键入retain、realeas、autorelease代码,编译器会在合适的地方自动帮我们插入retain、release、autorelease等方法的调用,从而完成对象的内存管理。但实际上除了编译器之外,ARC还用到了Runtime,比如weak指针的清空。这样就会在降低程序崩溃、内存泄漏风险的同时,很大程度程度减少了开发的工作量,使应用程序具有可预测性,且能流畅运行,速度也将大幅提升。具体来说,与MRC相对应,ARC帮我们做了如下三点:
利用
__strong指针修饰符,编译器会在合适的地方帮们插入retain、release、autorelease等方法的调用;利用属性修饰符,编译器为我们生成特定的
setter方法并处理好内部的内存管理,还会自动在dealloc方法里释放当前类及其父类的成员变量;利用
__weak指针修饰符和Runtime,来处理循环引入问题。
1.指针修饰符
__strong指针修饰符凡是用
__strong修饰的指针,在超出其作用域时,编译器会为我们插入一次release或autorelease的调用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// ARC下
{
__strong id obj = [[NSObject alloc] init];
__strong id arr = [NSArray array];
}
等价于:
// MRC下
{
id obj = [[NSObject alloc] init];
id arr = [[NSArray alloc] init];
[obj release];
[arr autorelease];
}
而在指针赋值时,编译器会自动为我们插入一次retain的调用。
1 | // ARC下 |
所以正是因为使用__strong指针修饰符,编译器才会在合适的地方帮我们插入retain、release、autorelease等方法的调用,而ARC下所有指针默认都是用__strong修饰的。
__weak指针修饰符
看起来有了strong,编译器就可以很好的管理内存了,但是很重要的一点是__strong无法解决引用计数式内存管理必然会导致的“循环引入”问题。
1 | // INEMan.h |
1 | // INEWoman.h |
1 | // ViewController.m |
viewDidLoad执行完,Man对象和Woman对象的dealloc方法都没走,也就是说它们俩都没销毁,这就是因为它们俩形成了循环引用,导致了内存泄漏。
但是只要我们把循环引用中的一个强指针的换成弱指针,就可以解决问题。
1 | @interface INEMan : NSObject { |
为什么能解决呢?这就要来看看**__weak指针的实现原理:**
__weak指针是专门用来解决循环引用问题的,它不是通过引用计数来管理对象的,而是通过弱引用表。具体地说:1.当我们把一个强指针赋值给一个弱指针时,编译器不会怒自动帮我们插入
retain使对象的引用计数+1,而是把这个弱指针和对象的内存地址绑在一起,通过两次散列算法找到弱引用计数表里的弱指针数组,然后把这个弱指针存到弱指针数组里。这样我们通过这些弱指针既可以正常使用该对象,又无需顾虑是不是要在什么时候把对象的引用计数-1,以免对象的引用计数>0而无法销毁,因为他没有参数引用计数那一套。2.当对象销毁时会走dealloc方法,又会通过两次散列算法找到弱引用计数表里的数组,把指向该对象的弱指针都置为
nil并移除。
2.属性修饰符
属性修饰符一共有三对儿:原子性、读写权限和内存管理语意,属性修饰符主要影响就是编译器为成员变量生成的setter、getter方法上。(这里除了讲解和内存相关的知识外,其他的也回顾一下)
原子性:
atomic(默认)、nonatomic
atomic:默认为atomic,使用atomic修饰的属性,编译器为该属性生成的setter、getter方法内部是加了锁的。1
2
3
4
5
6
7
8
9
10
11
12
13
14@property (atomic, strong) NSMutableArray *array;
- (void)setArray:(NSMutableArray *)array {
// 加锁
_array = array;
// 解锁
}
- (NSMutableArray *)array {
// 加锁
return _array;
// 解锁
}
但这仅仅是保证我们调用setter、getter方法访问属性这一步是线程安全的,它没发保证我们使用属性的线程是安全的,比如我们调用[self.array addObject:xxx],self.array访问属性这一步是线程安全的,但addObject:使用属性这一步是线程不安全的。
1 | // 线程1 |
所以为了保证使用属性的线程安全,我们还得在需要的地方自己加锁,这样一来使用使用atomic修饰属性就多此一举了,而且stter、getter方法的调用通常都是很频繁的,内部加锁的话会增加内存的开销,耗费性能。
1 | // 线程1 |
nonatomic:因此我们在实际开发中总是使用nonatomic。
读写权限:
readwrite(默认)、readonly
readwrite:默认为readwrite,代表该属性可读可写,编译器会为该属性生成setter
getter方法的声明与实现。
readonly:代表该属性只能读取不能写入,编译器会为该属性生成setter、getter方法的声明与getter方法的实现。
内存管理语意:
- MRC下有:
assign、retain、copy。- ARC下新增了:
strong、weak、unsafe_unretained。
assign:assign一般来修饰基本数据类型。使用assign修饰属性,编译器为属性生成的setter方法内部只是简单的赋值操作。
1 | - (void)setAge:(int)age { |
retain:retain一般用来修饰对象类型。使用retain修饰的属性,编译器为该属性生成的setter方法内部会调用一下retain方法,是对象的引用计数+1。1
2
3
4
5
6
7
8- (void)setDog:(Dog *)dog {
if (_dog != dog) { // 新旧对象不一样时
[_dog release]; // 释放旧对象
_dog = [dog retain]; // 持有新对象
}
}copy:copy一般用来修饰不可变属性和block。使用copy修饰的属性,编译器为该属性生成的setter方法内部会调用一下copy方法,生成一个新的对象,新对象的引用计数为1,而旧对象的引用计数不变。1
2
3
4
5
6
7
8- (void)setName:(NSString *)name {
if (_name != name) { // 新旧对象不一样时
[_name release]; // 释放旧对象
_name = [name copy]; // 复制新对象
}
}strong:默认为strong,大多数情况下和retain的效果是一样的,修饰block和copy的效果是一样的,strong一般用来修饰对象类型。weak:weak一般用来修饰代理对象和NSTimer,以免造成循环引入;还有用来修饰xib或sb拖出来的控件,因为这些界面已经被添加到界面上了,被subviews这个属性持有了,不必再用变量持有。unsafe_unretained:和assign效果是一样的,如果用他们来修饰对象类型,和weak功能类似,但weak修饰的属性会在对象销毁时会被置为nil,比较安全,而unsafe_unretained和assign修饰的属性则不会,所以容易出现野指针。