序言
弄明白对象、类、元类内存里存储的是什么东西就行
一、对象的本质
二、类的本质
三、元类的本质
四、分类的本质
2006年苹果发布了OC2.0,其中对Runtime的很多API做了改进,并把OC1.0中Runtime的很多API标记为“将来会被废弃”。 但是两套API的核心实现思路还是一样的,而旧API比较简单,所以我们会分析旧API,然后看看新API作了哪些变化,这里有最新的Runtime源码。
一、对象的本质
1、OC1.0
通过查看RunTIme的源码(objc.h文件),我们得到对象的定义如下(伪代码):
1
2
3
4
5
6
7
8
9
10
11
| struct objc_object {
Class isa;
NSSring *_name;
NSSring *_sex;
int _age;
};
typedef struct objc_object *id;
|
可见对象的本质就是一个objc_object类型的结构体。该结构体内部只有一个固定的成员变量isa,它是一个Class类型的结构体指针,存储着一个地址,指向该对象所属的类。当然结构体内部还可能有很多我们自定义的成员变量,存储着该对象这些成员变量具体的值。
2、OC2.0
通过查看Runtime的源码(objc-private.h文件),我们得到对象的定义如下(伪代码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| struct objc_object {
isa_t isa;
NSSring *_name;
NSSring *_sex;
int _age;
}
union isa_t {
Class cls;
unsigned long bits;
struct {
# if __arm64__
# define ISA_MASK 0x0000000ffffffff8ULL
unsigned long nonpointer : 1;
unsigned long has_assoc : 1;
unsigned long has_cxx_dtor : 1;
unsigned long shiftcls : 33;
unsigned long magic : 6;
unsigned long weakly_referenced : 1;
unsigned long deallocating : 1;
unsigned long has_sidetable_rc : 1;
unsigned long extra_rc : 19;
# endif
};
};
typedef struct objc_object *id;
|
可见对象的本质还是一个objc_object类型结构体。该结构体内部也还只有一个固定成员变量isa,只不过64位操作系统以后,对isa做了内存优化,它不再直接是一个指针,而是一个isa_t类型的共用体,它同样占用8个字节64位,但其中只有33位用来存储对象所属类的地址信息,还有19位用来存储(对象的引用计数 -1)、存储不下就放到引用计数表里,还有一位用来存储对象是否有弱引用,其他位上则存储这各种各样的标记信息。
nonpointer:占1位,标记isa是否经过内存优化。如果值为0,代表isa没经过内存优化,它就是一个普通的isa指针,64位全都用来存储该对象所属类的地址;如果值为1,代表isa经过了内存优化,只有33位用来存储对象所属类的地址信息,其它位则另有用途,了解一下即可;has_assoc:占1位,标记当前对象是否有关联对象,如果没有,对象销毁时会更快,了解一下即可;has_cxx_dtor:占1位,标记当前对象是否有C++析构函数,如果没有,对象销毁时会更快,了解一下即可;shiftcls:占33位,存储着当前对象所属类的地址信息;magic:占1位,用来标记在调试时当前对象是否未完成初始化,了解一下即可;weakly_referenced:占1位,标记弱引用表里是否有当前对象的弱指针数组——即当前对象是否被弱指针指向着、当前对象是否有弱引用;deallocating:占1位,标记当前对象是否正在释放,了解一下即可;has_sidetable_rc:占1位,标记引用计数表里是否有当前对象的引用计数;extra_rc:占19位,存储着(对象的引用计数 - 1),存不下了就会放到引用计数表里,存值范围为0~255。
二、类的本质
1、OC1.0
通过查看Runtime的源码(runtime.h文件),我们得到类的定义如下(伪代码):
可见类的本质就是一个objc_class类型的结构体,该结构体内部有若干个成员变量,其中有几个是我们重点关注的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| struct objc_class {
Class isa;
Class super_class;
method_array_t methods;
property_array_t properties;
protocol_array_t protocols;
const ivar_list_t *ivars;
cache_t cache;
const char *name;
long instance_size;
long version;
long info;
};
typedef struct objc_class *Class;
|
isa指针:存储着一个地址,指向该类所属的类——即元类;superclass指针:存储着一个地址,指向该类的父类;methods:数组指针,存储着该类所有的实例方法信息;properties:数组指针,存储着该类所有的属性信息;protocols:数组指针,存储着该类所有遵守的协议信息;ivars:数组指针,存储着该类所有的成员变量信息;cache:结构体,存储着该类所有的方法缓存信息。
2、OC2.0
通过查看Runtime的源码(objc-runtime-new.h文件),我们得到类的定义如下(伪代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| struct objc_class : objc_object {
// isa_t isa; // objc_class继承自objc_object,所以不考虑内存对齐的前提下,可以直接把isa成员变量搬过来
Class superclass;
class_data_bits_t bits; // 存储着该类的具体信息,按位与掩码FAST_DATA_MASK便可得到class_rw_t
cache_t cache;
}
// class_rw_t结构体就是该类的可读可写信息(rw即readwrite)
struct class_rw_t {
uint32_t flags;
uint32_t version;
const class_ro_t *ro; // 该类的只读信息
method_array_t methods; // 存储着该类所有的实例方法信息,包括分类的
property_array_t properties; // 存储着该类所有的属性信息,包括分类的
protocol_array_t protocols; // 存储着该类所有遵守的协议信息,包括分类的
Class firstSubclass;
Class nextSiblingClass;
char *demangledName;
}
// class_ro_t结构体就是该类的只读信息(ro即readonly)
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart;
uint32_t instanceSize;
#ifdef __LP64__
uint32_t reserved;
#endif
const uint8_t * ivarLayout;
const char * name;
method_list_t * baseMethodList; // 存储着该类本身的实例方法信息
protocol_list_t * baseProtocols; // 存储着该类本身遵守的协议信息
const ivar_list_t * ivars; // 存储着该类本身的成员变量信息
const uint8_t * weakIvarLayout;
property_list_t *baseProperties; // 存储着该类本身的属性信息
}
typedef struct objc_class *Class; // Class类型的本质就是一个objc_class类型的结构体指针,所以它可以指向任意一个OC类
|
可见类的本质还是一个objc_class类型的结构体,我们重点关注的那几个成员变量还是可以顺利找到的,只不过它内部结构套了两层rw和ro,我们先说一下ro,ro内部存储着经过编译后一个类本身定义的所有实例方法、属性、协议、成员变量,它是只读的,然后运行时才会生成rw,把ro里类本身定义的所有实例方法、属性、协议搞到rw里,并把这个类所有分类的实例方法、属性、协议合并到rw里,rw是可读写的,这在解释“分类为什么不能给类扩展成员变量”提供了一个很好的证据。
三、元类的本质
所谓元类,是指一个类所属的类,我们每创建一个类,系统就会自动帮我们创建好该类所属的类——即元类。如果你觉得不太好理解,这里就多说两句:我们常说“在面向对象编程里,万事万物皆对象”,因此在OC里对象其实分为实例对象、类对象、元类对象三类,我们开发中经常说的“对象”其实是指狭义的对象——实例对象,知道了这一点就好理解了,实例对象有它所属的类——即一个类对象,类对象也有它所属的类——即一个元类对象,元类对象也有它所属的类——即基类的元类对象。
其实元类和类的本质都是objc_class结构体,只不过它们的用途不一样,类的methods成员变量里存储着该类所有的实例方法信息,而元类的methods成员变量里存储着该类所有的类方法信息。
四、分类的本质
1、分类是什么,我们一般用分类做什么
分类是OC的一个高级特性,我们一般用它来给系统的类或三方库的类扩展方法、属性和协议,或者把一个类不同的功能分散到不同的模块里去实现。
举个简单例子:
比如我们给NSObject类扩展一个test方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| -----------NSObject+INETest.h-----------
#import <Foundation/Foundation.h>
@interface NSObject (INETest)
- (void)ine_test;
@end
-----------NSObject+INETest.m-----------
#import "NSObject+INETest.h"
@implementation NSObject (INETest)
- (void)ine_test {
NSLog(@"%s", __func__);
}
@end
|
比如我们有一个INEPerson类,保持它的主体,然后把它“吃”、“喝”的功能分散到不同的模块里去实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| -----------INEPerson.h-----------
#import <Foundation/Foundation.h>
@interface INEPerson : NSObject
@property (nonatomic, assign) NSInteger age;
@end
-----------INEPerson.m-----------
#import "INEPerson.h"
@implementation INEPerson
@end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| -----------INEPerson+INEEat.h-----------
#import "INEPerson.h"
@interface INEPerson (INEEat)
- (void)ine_eat;
@end
-----------INEPerson+INEEat.m-----------
#import "INEPerson+INEEat.h"
@implementation INEPerson (INEEat)
- (void)ine_eat {
NSLog(@"%s", __func__);
}
@end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| -----------INEPerson+INEDrink.h-----------
#import "INEPerson.h"
@interface INEPerson (INEDrink)
- (void)ine_drink;
@end
-----------INEPerson+INEDrink.m-----------
#import "INEPerson+INEDrink.h"
@implementation INEPerson (INEDrink)
- (void)ine_drink {
NSLog(@"%s", __func__);
}
@end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| -----------ViewController.m-----------
#import "INEPerson.h"
#import "INEPerson+INEEat.h"
#import "INEPerson+INEDrink.h"
- (void)viewDidLoad {
[super viewDidLoad];
INEPerson *person = [[INEPerson alloc] init];
[person ine_eat];
[person ine_drink];
}
|
分类和延展的区别:
- 分类一般用来给系统的类或三方库的类扩展方法、属性和协议,或者把一个类不同的功能分散到不同的模块里去实现;而延展一般用来给我们自定义的类添加私有属性。
- 分类的数据不是在编译时就合并到类里面的,而是在运行时;而延展的数据是在编译时就合并到类里面的。
2、分类的本质
通过查看Runtime的源码(objc-runtime-new.h文件),我们得到分类的定义如下:(伪代码)
1
2
3
4
5
6
7
8
9
10
| struct category_t {
const char *name; // 该分类所属的类的名字
struct classref *cls; // 指向该分类所属的类
struct method_list_t *instanceMethods;
struct method_list_t *classMethods;
struct protocol_list_t *protocols;
struct property_list_t *instanceProperties;
};
typedef struct category_t *Category;
|
可见分类的本质是一个category_t类型的结构体,该结构体内部有若干个成员变量,其中有几个是我们重点关注的:
classMethods:该分类为类扩展的类方法列表;instanceMethods:该分类为类扩展的实例方法列表;instanceProperties:该分类为类扩展的属性列表;protocols:该分类为类扩展的协议列表。
注意分类的本质里没有“该分类为类扩展的成员变量列表”喔,这在解释“为什么分类不能给类扩展成员变量”时又是一个很好的证据。
3、分类的实现原理
我们知道一个类所有的实例方法都存储在类里面,所有的类方法都存储在元类里面,而对象调用方法的流程就是根据isa指针先找到相应的类或元类,然后在类或元类里再找到相应的方法来调用,那person对象是怎么找到分类里的ine_eat和ine_drink方法来调用的呢?
现在我们可以大胆猜测,因为对象内部只有一个isa指针,指向它所属的类,所以不可能再有一套类似的方法查找机制让它专门去分类里面查找方法,难道系统会把分类里的方法合并到类里面去?如果会合并的话,那是编译时合并的,还是运行时合并的?很简单,我们只需要看看编译后类里面是否已经包含了分类的方法就行。
先给出结论:系统不是在编译时让编译器把分类的数据合并到类、元类里面的,而是在运行时利用Runtime动态把分类的数据合并到类、元类里面的,而且分类的数据还放在类本身数据的前面,越晚编译的分类越在前面,所以如果分类里面有和类里面同名的方法,会优先调用分类里面的方法,如果多个分类里面有同名的方法,会优先调用后编译分类里面的方法,我们可以去Compile Sources里控制分类编译的顺序。
- 系统不是在编译时让编译器把分类的数据合并到类、元类里面的
接着上面INEPerson类的例子,我们用clang编译器把INEPerson.m文件转换成C/C++代码,以便窥探编译后INEPerson类里面是否已经包含了分类的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| struct objc_class OBJC_CLASS_$_INEPerson = {
0, // &OBJC_METACLASS_$_INEPerson,
0, // &OBJC_CLASS_$_NSObject,
0, // (void *)&_objc_empty_cache,
// 可读可写的
["age", "setAge:"], // 所有的实例方法
["age"], // 所有的属性
[], // 所有遵循的协议
// 只读的
"INEPerson", // 类名
["_age"], // 所有的成员变量
16, // 实例对象的实际大小
};
|
可见经过编译后,INEPerson类里面的数据还是它本身拥有的那些数据,并没有分类的方法,这就表明系统不是在编译时让编译器把分类的数据合并到类、元类里面的。
- 而是在运行时利用Runtime动态把分类的数据合并到类、元类里面的
既然系统不是在编译时就把分类的数据合并到类里面的,那就只能是在运行时了,接下来我们就找找运行时(Runtime)的相关源码(objc-runtime-new.mm文件),看看系统到底是怎么把分类合并到类里面的:
运行时,系统读取镜像阶段,会读取所有的类,并且如果发现有分类,也会读取所有的分类,然后遍历所有的分类,根据分类的cls指针找到它所属的类,重新组织一下这个类的内部结构——即合并分类的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // 系统读取镜像
void _read_images()
{
// 读取所有的类
// ...
// 发现有分类
// 读取所有的分类
category_t **catlist = _getObjc2CategoryList(hi, &count);
// 遍历所有的分类
for (i = 0; i < count; i++) {
// 读取某一个分类
category_t *cat = catlist[I];
// 根据分类的cls指针找到它所属的类
Class cls = cat->cls;
// 重新组织一下这个类的内部结构——即合并分类的数据
remethodizeClass(cls);
}
}
|
那具体怎么个合并法呢?系统会去获取这个类所有的分类,然后倒序遍历这所有的分类,把每个分类里面的实例方法列表拿出来,存进一个二维数组里(因为是倒序遍历分类的,所以越晚编译的分类的实例方法列表反而越会放在二维数组的前面),然后再把这个二维数组内所有一维数组的首地址复制进methods成员变量指向的那块内存里(注意这个存储过程会把类本身的实例方法列表挪到最后——即高内存地址上,而把分类的实例方法列表存在前面)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| // 重新组织一下这个类的内部结构——即合并分类的数据
static void remethodizeClass(Class cls)
{
// 系统会去获取这个类所有的分类(没有合并过的)
category_list *cats = unattachedCategoriesForClass(cls);
// 把所有分类的数据合并到类里面
attachCategories(cls, cats);
free(cats);
}
/**
* 把所有分类的数据合并到类里面
*
* @param cls 当前类
* @param cats 当前类所有的分类
*/
static void attachCategories(Class cls, category_list *cats)
{
#pragma mark - 倒序遍历所有的分类,把每个分类里面的实例方法列表拿出来,存进一个二维数组里
/*
创建一个二维数组,用来存放每个分类里的实例方法列表,最终结果类似下面这样:
[
[instanceMethod1, instanceMethod2, ...] --> 分类1所有实例方法
[instanceMethod1, instanceMethod2, ...] --> 分类2所有实例方法
...
]
*/
method_list_t **mlists = (method_list_t **) malloc(cats->count * sizeof(*mlists));
// 属性
property_list_t **proplists = (property_list_t **) malloc(cats->count * sizeof(*proplists));
// 协议
protocol_list_t **protolists = (protocol_list_t **) malloc(cats->count * sizeof(*protolists));
int mcount = 0;
int propcount = 0;
int protocount = 0;
int i = cats->count;
// 注意:这里是倒序遍历所有的分类
while (i--) {
// 获取一个分类
auto cat = cats[I];
// 获取分类的实例方法列表,存进二维数组
method_list_t *mlist = cat->methods;
mlists[mcount++] = mlist;
// 属性
protocol_list_t *protolist = cat->protocols;
protolists[protocount++] = protolist;
// 协议
property_list_t *proplist = cat->properties;
proplists[propcount++] = proplist;
}
#pragma mark - 把这个二维数组内所有一维数组的首地址存进methods成员变量所指向的那块内存空间里
// 获取当前类的数据(包括实例方法列表、属性列表、协议列表等)
auto classData = cls->data();
// 给当前类的实例方法列表附加所有分类的实例方法列表
classData->methods.attachLists(mlists, mcount);
free(mlists);
// 属性
classData->properties.attachLists(proplists, propcount);
free(proplists);
// 协议
classData->protocols.attachLists(protolists, protocount);
free(protolists);
}
/**
* 给当前类的实例方法列表附加所有分类的实例方法列表
*
* @param addedLists 所有分类的实例方法列表(就是那个二维数组,但其实是那个二维数组的首地址)
* @param addedCount 分类的个数
*/
void attachLists(List* const * addedLists, unsigned int addedCount) {
#pragma mark - 重新为类的methods成员变量分配内存
// 获取类原来methods成员变量的元素个数(注意:一个类的methods成员变量是一个数组,存储着若干个指针,指向相应的方法列表,而不是直接就是个方法列表存储方法)
unsigned int oldCount = array()->count;
// 加上分类的个数,得到新的methods成员变量该有多少个元素
unsigned int newCount = oldCount + addedCount;
// 重新为methods成员变量所指向的数组分配内存,一个指针占8个字节
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
array()->count = newCount;
#pragma mark - 为类的methods成员变量重新分配完内存后,对其内存数据进行移动和复制操作
//
/*
内存复制:
memmove(dst, src, len),从src所指向的内存空间复制len个字节的数据到dst所指向的内存空间,内部处理了内存覆盖。
memcpy(dst, src, n),从src所指向的内存空间复制n个字节的数据到dst所指向的内存空间,内部没处理内存覆盖。
*/
// 把类原来的实例方法列表复制到最后面(但其实是把类原来的实例方法列表,在methods成员变量里对应的那个指针————原来的实例方法列表的首地址————复制到最后面了)
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[0]));
// 把所有分类的实例方法列表放在前面(同理,其实是把所有分类的的实例方法列表的首地址复制到前面了,因为methods成员变量里存放的是指针————即实例方法列表的地址,不过这里二维数组的内存拷贝会拷贝它里面所有一维数组的首地址,而不仅仅这个二维数组的首地址)
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
|
这样就把所有分类的实例方法列表全都合并到类里面去了,最终类的方法列表结构如下:
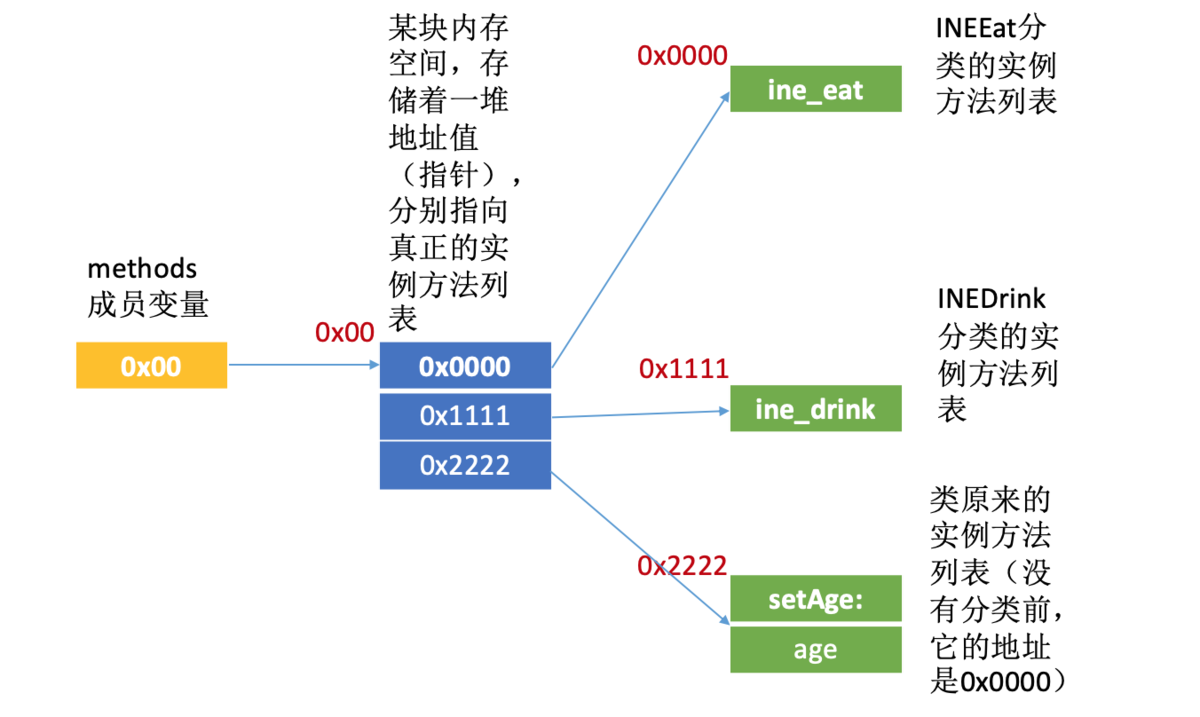
以上我们只是说明了分类为类扩展实例方法的底层实现,至于分类为类扩展类方法、属性、协议是同理的。
4、分类的+load方法和+initialize方法
|
调用时机 |
调用方式 |
调用顺序 |
+load方法 |
+load方法是系统把类和分类载入内存时调用的 |
+load方法是通过内存地址直接调用的,所以分类的+load方法不会覆盖类的+load方法,也就是说如果类和分类里面都实现了+load方法,那么它们都会被调用 |
会先调用所有类的+load方法,然后再调用所有分类的+load方法 |
+initialize方法 |
+initialize方法是类初始化的时候调用的 |
+initialize方法是通过消息发送机制调用的,所以分类的+initialize方法会覆盖类的+initialize方法,也就是说如果类和分类里面都实现了+initialize方法,那么只有分类里面的会被调用 |
会优先调用分类的+initialize方法 |
苹果提供类、分类的+load方法和+initialize方法,其实就是给我们开发者暴露两个接口,让我们根据这俩方法的特点来合理使用。比如我们想在某个类被载入内存时做一些事情,就可以在+load方法里做操作,想在某个类初始化时做一些事情,就可以在+initialize方法里做操作。
4.1 +load方法
假设有一个INEPerson类,并且为它创建了两个分类INEEat和INEDrink。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| -----------INEPerson.m-----------
#import "INEPerson.h"
@implementation INEPerson
+ (void)load {
NSLog(@"INEPerson +load");
}
@end
-----------INEPerson+INEEat.m-----------
#import "INEPerson+INEEat.h"
@implementation INEPerson (INEEat)
+ (void)load {
NSLog(@"INEPerson (INEEat) +load");
}
@end
-----------INEPerson+INEDrink.m-----------
#import "INEPerson+INEDrink.h"
@implementation INEPerson (INEDrink)
+ (void)load {
NSLog(@"INEPerson (INEDrink) +load");
}
@end
|
我们什么都不做,不使用Person类,甚至连它的头文件也不导入。
1
2
3
4
5
6
7
8
9
10
11
12
| -----------ViewController.m-----------
#import "ViewController.h"
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
}
@end
|
直接运行程序,发现控制台打印如下:
1
2
3
| INEPerson +load
INEPerson (INEEat) +load
INEPerson (INEDrink) +load
|
于是我们就可以得出结论:**+load方法是系统把类和分类载入内存时调用的,它和我们代码里使用不使用这个类和分类无关。并且因为+load方法只会在类和分类被载入内存时调用,所以每个类和分类的+load方法在程序的整个生命周期中肯定会被调用且只调用一次。**
这里先回想一下,上面第三部分我们说过分类的方法列表会合并到类本身的方法列表里,并且分类的方法列表还会在类本身方法列表的前面,因此分类的方法会覆盖掉类里同名的方法。
但不知道你注意没有,上面第1小节的例子,控制台打印了三个东西,也就是说分类的+load方法和类的+load方法都走了,这很奇怪啊,按理说应该只走其中某一个分类的+load方法才对啊,怎么会三个都走呢?也就是说为什么分类的+load方法没有覆盖掉类的+load方法?
接下来我们就找找运行时(Runtime)的相关源码(objc-runtime-new.mm文件),看看能不能得到答案:(伪代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
void load_images()
{
call_load_methods();
}
void call_load_methods()
{
call_class_loads();
call_category_loads();
}
static void call_class_loads()
{
struct loadable_class *classes = loadable_classes;
for (int i = 0; i < loadable_classes_used; i++) {
Class cls = classes[i].cls;
load_method_t load_method = (load_method_t)classes[i].method;
(*load_method)(cls, SEL_load);
}
}
static void call_category_loads()
{
struct loadable_category *cats = loadable_categories;
for (i = 0; i < loadable_categories_used; i++) {
Category cat = cats[i].cat;
load_method_t load_method = (load_method_t)cats[i].method;
(*load_method)(cls, SEL_load);
}
}
|
可见**+load方法是通过内存地址直接调用的,而不像普通方法那样走消息发送机制。因此就解释了我们留下的疑惑,虽然说分类的方法列表在类本身方法列表的前面,但是对+load方法根本不起作用,人家不走你那一套,所以分类的+load方法不会覆盖类的+load方法。**
这里就直接给出结论了,感兴趣的话,可以像第2小节那样去看源码(核心代码就集中在上面那几个方法里)并敲代码验证验证。
会先调用所有类的+load方法,先编译的类先调用;如果存在继承关系,那么在调用子类的+load方法之前会先去调用父类的+load方法。
然后再调用所有分类的+load方法,先编译的分类先调用。
4.2 +initialize方法
假设有一个INEPerson类和一个继承自INEPerson类的INEStudent类,并且为INEStudent类创建了两个分类INEEat和INEDrink。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| -----------INEPerson.m-----------
#import "INEPerson.h"
@implementation INEPerson
+ (void)initialize {
NSLog(@"INEPerson +initialize");
}
@end
-----------INEStudent.m-----------
#import "INEStudent.h"
@implementation INEStudent
+ (void)initialize {
NSLog(@"INEStudent +initialize");
}
@end
-----------INEStudent+INEEat.m-----------
#import "INEStudent+INEEat.h"
@implementation INEStudent (INEEat)
+ (void)initialize {
NSLog(@"INEStudent (INEEat) +initialize");
}
@end
-----------INEStudent+INEDrink.m-----------
#import "INEStudent+INEDrink.h"
@implementation INEStudent (INEDrink)
+ (void)initialize {
NSLog(@"INEStudent (INEDrink) +initialize");
}
@end
|
我们什么都不做,直接运行程序,发现控制台什么都没打印。
1
2
3
4
5
6
7
8
9
10
11
12
| -----------ViewController.m-----------
#import "ViewController.h"
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
}
@end
|
此时我们调用一下Student类的+alloc方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
| -----------ViewController.m-----------
#import "ViewController.h"
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
[INEStudent alloc];
}
@end
|
运行程序,发现控制台打印如下:
1
2
| INEPerson +initialize
INEStudent (INEDrink) +initialize
|
于是我们就可以得出结论:**+initialize方法是类初始化的时候调用的,所以严格地来讲,我们不能说“+initialize方法是第一次使用类的时候调用的”,你看上面例子中我们根本没使用INEPerson类嘛,但它的+initialize方法照样被调用了。如果我们压根儿不使用这个类,它的+initialize方法被调用0次,但是我们不能说一个类的+initialize方法最多被调用1次,因为+initialize方法是通过消息发送机制来调用的,如果好几个子类都继承自某一个类,而这些子类都没有实现自己的+initialize方法,那就都会去调用这个父类的+initialize方法,这不就是调用N次了嘛。**
上面第1小节的例子,控制台打印了一个:
1
| INEStudent (INEDrink) +initialize
|
这就明显表明:**+initialize方法的调用方式不同于+load方法,它是通过消息发送机制调用的,所以才会只走分类里面的 +initialize方法,也就是说分类的+initialize方法会覆盖类的+initialize方法。**
但有一点很奇怪,因为控制台还打印了:
这是父类的+initialize方法呀!既然+initialize方法是通过消息发送机制调用的,那它在自己类的内部找到某个方法后,就不应该再调用父类里面的方法了呀,怎么回事?
接下来我们就找找运行时(Runtime)的相关源码(objc-runtime-new.mm文件),看看能不能得到答案:(伪代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
IMP lookUpImpOrForward(Class cls, SEL sel)
{
if (!cls->isInitialized()) {
initializeNonMetaClass(cls);
}
}
void initializeNonMetaClass(Class cls)
{
Class supercls = cls->superclass;
if (supercls && !supercls->isInitialized()) {
initializeNonMetaClass(supercls);
callInitialize(cls);
} else {
initializeNonMetaClass(cls);
callInitialize(cls);
}
}
void callInitialize(Class cls)
{
((void(*)(Class, SEL))objc_msgSend)(cls, SEL_initialize);
}
|
可见系统在调用一个类的+initialize方法之前,首先会看看它的父类初始化了没有,如果没有初始化,则初始化它的父类并调用它父类的+initialize方法,然后再初始化自己并调用自己的+initialize方法;如果它的父类初始化了,则直接初始化自己并调用自己的+initialize方法,如果自己没有实现,则会去找父类的+initialize方法调用。
这里就直接给出结论了。
系统在调用一个类的+initialize方法之前,首先会看看它的父类初始化了没有,如果没有初始化,则初始化它的父类并调用它父类的+initialize方法,然后再初始化自己并调用自己的+initialize方法;如果它的父类初始化了,则直接初始化自己并调用自己的+initialize方法,如果自己没有实现,则会去找父类的+initialize方法调用。
如果分类里也实现了+initialize方法,会优先调用分类的。
temp、行文至此,我们举个例子串一下上面的内容
定义一个INEPerson类,并为它创建一个分类INEDrink,然后创建两个person对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| -----------INEPerson.h-----------
#import <Foundation/Foundation.h>
@interface INEPerson : NSObject <NSCopying>
@property (nonatomic, copy) NSString *name;
@property (nonatomic, copy) NSString *sex;
@property (nonatomic, assign) NSInteger age;
- (void)eat;
+ (void)sleep;
@end
-----------INEPerson.m-----------
#import "INEPerson.h"
@implementation INEPerson
- (void)eat {
NSLog(@"对象方法:吃");
}
+ (void)sleep {
NSLog(@"类方法:睡");
}
- (id)copyWithZone:(nullable NSZone *)zone {
return self;
}
@end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| -----------INEPerson+INEDrink.h-----------
#import "INEPerson.h"
@interface INEPerson (INEDrink)
- (void)ine_drinkWater;
+ (void)ine_drinkTea;
@end
-----------INEPerson+INEDrink.m-----------
#import "INEPerson+INEDrink.h"
@implementation INEPerson (INEDrink)
- (void)ine_drinkWater {
NSLog(@"%s", __func__);
}
+ (void)ine_drinkTea {
NSLog(@"%s", __func__);
}
@end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| -----------ViewController.m-----------
#import "ViewController.h"
#import "INEPerson.h"
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
INEPerson *person1 = [[INEPerson alloc] init];
person1.name = @"张三";
person1.sex = @"男";
person1.age = 19;
[person1 eat];
INEPerson *person2 = [[INEPerson alloc] init];
person2.name = @"李四";
person2.sex = @"女";
person2.age = 18;
[INEPerson sleep];
}
@end
|
当我们启动App时,系统就会把INEPerson类、INEPerson类的元类还有INEPerson类的分类加载到内存中,然后把分类的数据合并到类和元类里,并且这些类会被存储到静态全局区,因为类只要一份就够了嘛 + 类还得能在项目的任何地方都能访问到,直到杀死App,这些类的内存才会被释放。那么INEPerson类在静态全局区的那块内存里存储着什么呢?isa指针存储着一个地址,指向INEPerson类的元类,这个地址就是INEPerson类的元类在静态全局区的内存地址;superClass指针存储着一个地址,指向NSObject类,这个地址就是NSObject类在静态全局区的内存地址;methods成员变量存储着ine_drinkWater和eat这两个实例方法的信息,properties成员变量存储着name、sex、age这些属性的信息,protocols成员变量存储着NSCopying协议的信息,ivars成员变量存储着_name、_sex、_age这些成员变量的信息,cache缓存着eat方法的信息。INEPerson类的元类在静态全局区的那块内存里存储着什么呢?isa指针存储着一个地址,指向基类NSObject类的元类,这个地址就是基类NSObject类的元类在静态全局区的内存地址;superClass指针存储着一个地址,同样指向基类NSObject类的元类,这个地址就是基类NSObject类的元类在静态全局区的内存地址;methods成员变量存储着ine_drinkTea和sleep这个类方法的信息,cache缓存着sleep方法的信息。
当我们alloc init一个person对象时,就会在堆区分配一块内存,直到没有强引用引用这个对象了,这块内存才会被释放。那么person对象在堆区的那块内存里存储着什么呢?isa指针存储着一个地址,指向INEPerson类,这个地址就是INEPerson类在静态全局区的内存地址;person1对象接下来会存储_name成员变量的值”张三”,当然它存储的也是一个常量区的地址,指向”张三”这个字符串常量,还有_sex成员变量的值”男”,当然它存储的也是一个常量区的地址,指向”男”这个字符串常量,还有_age成员变量的值“19”,当然“19”就是直接存储了,因为它是个立即数;person2对象接下来则会存储_name成员变量的值”李四”,_sex成员变量的值”女”,_age成员变量的值“18”,注意对象的内存里存储的是成员变量的值,而类的内存里存储的是成员变量的信息——比如INEPerson类有一个成员变量是“_name”,它的类型是NSString这样。